
Generative AI Art — Understanding Beyond the AI Algorithm
The generative artificial intelligence art (AI Art) is a very broad topic, and with this simple blog post, it would be challenging to cover the full context of the AI Art, as the history of each AI Art technique alone can be written into several blog posts in timeline sequence.
This blog post covers the stories behind AI Art and fundamental mechanisms of major AI Art techniques with hands-on exercises in python. After reading this blog post, hopefully, you feel that the AI Art is not only magical, but also not so challenging to experiment.
Introduction
Data science is about storytelling from data — in the business context, the significant insights from data are visualized and narrated to communicate effectively, which triggers decisive actions from the audience, and business actions lead to forecasting the future. This process can be transpired in the art world, where data science tells stories about our emotion that further provokes our imagination. These stories from millions of data points become the vision of our world, which then points to show us the vision of our future.
“ Anything that the machine needs to understand life can become material for the imagination” by Refik Anadol, media artist pioneer in the aesthetics of machine intelligence
The connection between AI and art created the major breakthrough in the art history by pushing beyond the boundary of the artistic creativity that human can go and by revolutionizing the art business — it is already changing the way that the art pieces are created, enabling anyone to become a master artist as well as the way that art appraisals, auction sales and art exhibitions and fairs are conducted.
Furthermore, the popularity of the AI Art has escalated rapidly in recent years, which was also fueled by the COVID-19 pandemic that has dramatically accelerated the digital transition of the art market in 2020 and 2021.
This trend can be best illustrated in the following bar plot, where the search interest on specific keywords such as ‘Generative AI Art’ in Google over time from 2004 to 2021 is visualized. As you can see, the interest in web search has drastically grown over time from 2010 and 2012, and increased significantly in 2020 and foremost in 2021.

Along with the increasing interest in ‘Generative AI Art’, its commercial interest has also grown significantly over the years with the auction prices ranging from $10,000 to $430,000.
Although not all the AI artworks are commercialized, there have been the surge of creative visual art images from AI being shared in Twitter, Reddit and other social media platforms, and new AI Art code is emerging almost every week, mostly shared by AI-hobbyist, data scientists and enthusiasts.
Yes, AI Art already sounds so fascinating, and it is about time to know what it is.
What is AI Art?
The term, AI Art, really means the Generative Art. In Wikipedia term, “AI Art refers to any artwork created through the use of artificial intelligence.”
AI Art uses deep learning and computer vision technology with tasks of image classification, feature extraction, object detection, segmentation and generative models as follows:
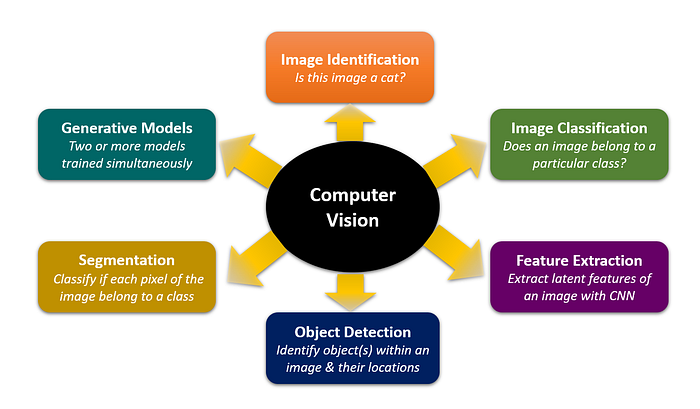
AI in the Visual Art Domain
It is not all new to talk about AI in the art domain. AI Art has been with us for decades, where it evolved and gained greater attention in recent years. AI technologies are used in analyzing existing art, mapping or recovering historical art work, creating new art and enhancing both physical and mental health well-being, where the art therapy is now considered as one of the non-pharmacological treatments for dementia and even prescribed under the National Health Service in some countries such as Canada.
How Has AI Art Evolved?
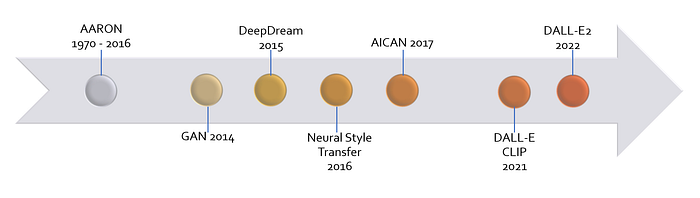
AARON (1970–2016)
One of the first primary art systems by AI was AARON , which is the collective name for a series computer programs using C programming language and Lisp, developed by Harold Cohen for the purpose of creating the original artistic images. This system was introduced in the late 1960’s and in development between 1972 and 2016. AARON was not open source, and the development of this system ended when Cohen passed away.

GAN (2014)
The current rise of AI Art was ignited with the introduction of a generative adversarial network (GAN) through the Pd.D. dissertation, written by Ian Goodfellow and his colleagues in June 2014. Machine learning and especially in deep learning with neural nets, were well advanced by then, but images generated from machine learning were quite blurry or missing certain parts of images, and machine learning was not able to come up with images by themselves. Goodfellow’s colleagues were trying to work on this problem by using complex statistical analysis. On a fateful night at a brewpub in Montreal in 2014, while Goodfellow and his colleagues were discussing, Goodfellow came up with an idea of two neural networks working against each other. Overnight, code was written and GAN was invented, marking Goodfellow as a creator and AI celebrity.
GAN redefine the look of the contemporary AI Art, and has been used for many applications for creating or recreating photo images and videos in astronomical and medical science, video games, media and state-of-art transfer learning research.

DeepDream (2015)
About a year after the creation of GAN, Alexander Mordvintsev, an engineer in the Google SafeSearch team in Zürich, typed lines of code early in the morning in May 2015, which became another hallmark discovery in the history of AI. Assuming that they would not be noticed, Mordvintsev posted images from his code in Google before his sleep. On the contrary, these images became viral on that very day, which are now known as DeepDream, psychedelic, hallucinogenic, dream-like, over-processed images with complex geometric patterns in the background. The crucial point of this discovery was the fact that the machine was not programmed into producing these images.
“The background had been transformed into complex geometric patterns, with a couple of spiders bursting through. It seems the machine saw spiders there, even though we hadn’t. It was a vision of the world through the eyes of the machine.” by Alexander Mordvintsev (from The MIT Press Reader)
The discovery of DeepDream images was not by sheer coincidence — Mordvintsev’s passion was in finding out how and why the convolutional neural nets (CNN) worked and what went on in the hidden layers, and he refused to see these layers as a black box, unlike most data scientists at that time. A team of researchers at Oxford University had published papers early on, providing clues to these questions by investigating CNN. They also observed features of the original images in a particular layer and generated those features in the form of pixels, producing blurry images that resembled a target image. Mordvintsev went deeper, layer by layer, and differentiated his investigative work from the Oxford team by generating images for each layer, while the neural network was still in the process of verifying a particular pattern that could be a target object. With his first image being a mix of a cat and a beagle, he pre-trained the image on ImageNet, repeated his process and generated more visionary images. These images became sensational in the AI world.
His work at Google was not associated with computer vision at the time of his discovery, but his enthusiasm had been in computer vision from his prior work at a company specializing in marine-training simulators, where he used to use computers to model biological systems. His discovery connected him to his passion once again.

Neural Style Transfer (2016)
The work of deep learning was progressing — the original, large ImageNet classification dataset was developed by a team in Stanford University, and in 2012, the research paper published by a team at University of Toronto demonstrated the new CNN that dealt with various vision problems by learning diverse “features” with the statistics of natural images of the original ImageNet dataset. This development sparked another surge of the creative AI Art that used deep CNNs.
“Could the new deep network features explain human texture perception?”
With this question in mind, in 2015, Leon Gatys, a neuroscience graduate student at University of Tübingen in Germany at that time, revisited the texture synthesis, and worked with his collaborators from Switzerland and Belgium on the application of the statistical representation to much richer deep networks, and improved the previous texture synthesis algorithms by capturing various large-scale structures as texture. The research paper of his team’s work, “Texture Synthesis Using Convolutional Neural Networks”, was published in the same year.

“Could neural networks also work for image stylization?”
This question led Gatys and his collaborators to work on the slower algorithm to produce an image with the texture of the painting on the content of a photo image, and to design the Neural Algorithm of Artistic Style as follows:
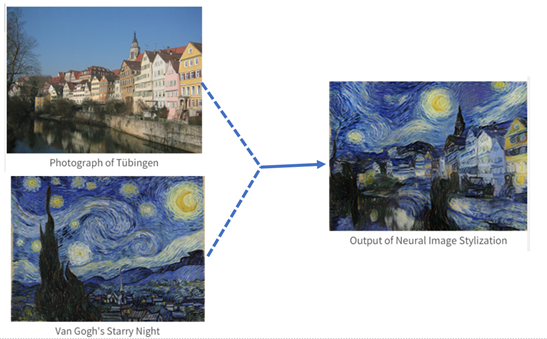
His team’s work on NST was published in 2015 and subsequently accepted by the peer-reviewed CVPR conference in 2016.
“The system uses neural representations to separate and recombine content and style of arbitrary images, providing a neural algorithm for the creation of artistic images.” by Leon Gatys

AICAN (2017)
The foundation of AI Art was redefined through AI Creative Adversarial Network (CAN), created by Dr. Ahmed Elgammal and his team, where he is a professor of computer science at Rutgers University and the founder and director of the Art and Artificial Intelligence Laboratory. Dr. Elgammal and his colleagues continue to develop technologies for generating new AI Art in this lab.
CAN is derived from GAN, but its focus is more on the creativity — GAN has the effect of re-paining or re-creating the already existing artistic images, whereas CAN can create the completely new work of art, which is made possible by two different components from GAN — signals and discriminator.
CAN receives two signals, whereas GAN receives only one signal — one signal is the same as GAN, where it determines the image object similar to the training dataset and style attribute. The other signal conveys the closeness of the generated image to a particular style, which is unique to CAN and determining factor for creative work.
Discriminator in CAN plays a significant role for enhancing creativity by passing the second signal to a generator that is not similar to the style of images in training dataset. This process magnifies the obscurity in impressionism.

CLIP, DALL-E & DALL-E2
Developed by OpenAI, one of the world’s most ambitious AI labs founded by Elon Musk, Sam Altman and others in San Francisco in late 2015, CLIP, DALL-E and DALL-E2 were released in 2021 and 2022. They are all the cutting-edge, AI technology based on a neural network and diffusion model.
CLIP (2021)
Along with DALL-E, OpenAI’s CLIP is considered the most significant advancement in computer vision in 2021. It is a multimodal model that combines the knowledge of English-language concepts with semantic knowledge of images (roboflow blog September 2021).
In contrast to traditional computer vision models that only take a numeric identifier, where the context of the models’ labels are lost by being converted to a numeric sequence, CLIP holds the context of text and images as inputs with its ability to understand the meaning of English phrases and the representation of certain pixels. For example, CLIP can distinguish between two images of a cat and a dog and between two different phrases of “an illustration of Deadpool pretending to be a bunny rabbit” and “an underwater scene in the style of Vincent Van Gogh” without seeing these in its training dataset.
CLIP has the list of use cases other than image generation, which continues to grow since its release in January 2021.
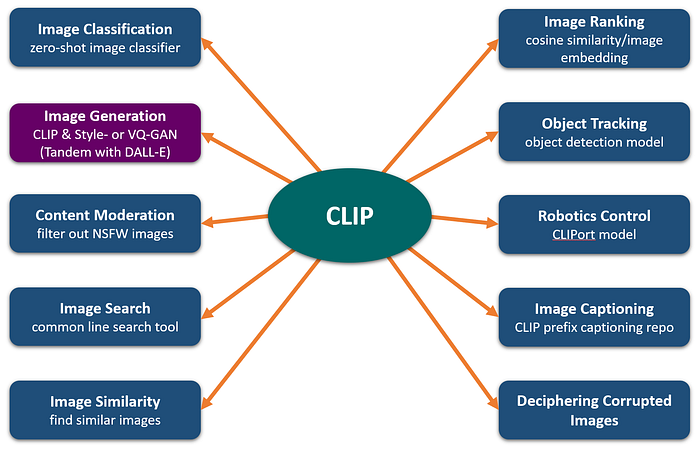
More details about CLIP and its tutorial are available in this link.

DALL-E (2021)
Creating AI Art became much simple process through a mere text prompt by DALL-E, which transformed the outlook of the contemporary art.
Developed in tandem with CLIP as a separate program, DALL-E creates high-resolution, often hyper-imaginative and hyper-realistic, digital images by simple description of what users have in mind. This technology was enabled by an AI program that is a 12-billion parameter version of GPT-3 and a transformer language model — it takes both the text, natural language inputs, and the image as a single stream of data that contains up to 1,280 tokens, and generates corresponding images from scratch after being trained using maximum likelihood to generate all of the tokens.
The acronym, DALL-E, is originated from WALL-E, an autonomous robot in the 2008 Pixar’s CGI feature film and Salvador Dali, Spanish Surrealist painter. I can see that these sources well represent the surreal nature of the created images from the system.


DALL-E2 (2022)
OpenAI announced its release of DALL-E2 at Twitter on April 6, 2022, which is the upgraded version of DALL-E.
The previous version, DALL-E, mostly generated cartoon-like images on a plain background, whereas the newer version, DALL-E2, is capable of generating photo-quality images in much higher resolution with diverse and more sophisticated backgrounds from a simple description of a few words. Its run time for generating these images is much shorter than DALL-E as well.
As DALL-E2 understands the relationship between images and text inputs better than DALL-E, it can either generate an original image in a wide range of style variations or create completely new images or even paintings. Editing an image is also much easier under DALL-E2 by simply specifying a part of the image with a box that users want to modify and making natural-language instructions for modification.

OpenAI was trying to create artificial general intelligence (AGI), a AI software program that can perform like or better than human-level intelligence for a wide range of tasks. To accomplish this, AGI would need to be able to draw the connection between a word and an associated image or set of images, which can be described as “multimodal” conceptual understanding. DALL-E2 was an important step toward AGI, which has been the goal of OpenAI.
Mechanics of AI Art
In this section, the following three fundamental AI techniques are discussed, including the very simple, hands-on experiement for DeepDream and NST, based on the TensorFlow Tutorial:
- Generative Adversarial Network (GAN)
- DeepDream
- Neural Style Transfer (NST)
Generative Adversarial Network (GAN)
As a type of unsupervised learning, which is trained by self-supervised learning, GAN’s main use-case is to classify if a target object is real.
Its algorithmic architecture involves two neural networks: a generatorfor generating new, synthetic examples of data that are passed on to a discriminatorfor classifying whether those examples of data are real or not. These neural networks are pitting against each other, thereby forming ‘adversarial’ structure.
GAN is widely used in the generation of image, video and voice.
GAN takes the following main steps:
- The generator takes in random numbers and returns an image.
- This generated image is fed into the discriminator alongside a stream of images taken from the actual dataset.
- The discriminator takes in both real and fake images and returns probabilities, a number between 0 and 1, with 1 representing a prediction of authenticity and 0 representing fake.
GAN has the two main components, based on the double feedback loop as follows:
- The discriminator is in a feedback loop with the actual images, which we know.
- The generator is in a feedback loop with the discriminator.

DeepDream
DeepDream enables the visualization of the patterns learned by a neural network.
It does so by forwarding an image through the neural network, then calculating the gradient of the image with respect to the activations of a particular layer. The image is then modified to increase these activations, enhancing the patterns seen by the network, and resulting in a dream-like image. This process was also referred to as “Inceptionism”.
The main processes involved in DeepDream are as follows:
- Artificial Neural Networks — image classification
- Gradually adjusting the network parameters
- Neural networks that were trained to discriminate between different kinds of images have quite a bit of the information needed to generate.

Here are some more examples across different classes:

DeepDream — Hands-On Experiment with Python:
We are using this input image file: data
Hands-on code for DeepDream is from this TensorFlow Tutorial.
Let’s import the following python libraries:
import tensorflow as tfimport numpy as npimport matplotlib as mplimport IPython.display as displayimport PIL.Image
Let’s upload the input image:
filename = '/content/nicole_violin.png'nicole_image = Image.open(filename)nicole_image.show()
Let’s set up the functions to download and read the image into numpy array, normalize, display and downsize the image to the easier work:
# Download an image and read it into a NumPy array.def download(image_path, max_dim=None): img = PIL.Image.open(image_path) if max_dim: img.thumbnail((max_dim, max_dim)) return np.array(img)# Normalize an imagedef deprocess(img): img = 255*(img + 1.0)/2.0 return tf.cast(img, tf.uint8)# Display an imagedef show(img): display.display(PIL.Image.fromarray(np.array(img)))# Downsizing the image makes it easier to work with.original_img = download(filename)show(original_img)
Then, we need to download and prepare a pre-trained image classification model. We will use InceptionV3, which is similar to the model originally used in DeepDream. Note that any pre-trained model will work, although you will have to adjust the layer names below if you change this.
# prepare feature extraction modelbase_model = tf.keras.applications.InceptionV3(include_top=False, weights='imagenet')Output:Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/inception_v3/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
87916544/87910968 [==============================] - 1s 0us/step
87924736/87910968 [==============================] - 1s 0us/step
The InceptionV3 architecture is quite large. For DeepDream, the layers of interest are those where the convolutions are concatenated. There are 11 of these layers in InceptionV3, named ‘mixed0’ though ‘mixed10’. Using different layers will result in different dream-like images. Deeper layers respond to higher-level features (such as eyes and faces), while earlier layers respond to simpler features (such as edges, shapes, and textures).
# Maximize the activation of these layersnames = ['mixed3', 'mixed5']layers = [base_model.get_layer(name).output for name in names]# Create the feature extraction modeldream_model = tf.keras.Model(inputs=base_model.input, outputs=layers)
In the next step, we need to calculate the loss., where the loss is the sum of the activations in the chosen layers. The loss is normalized at each layer so the contribution from larger layers does not outweigh smaller layers. In DeepDream, we will maximize this loss via gradient ascent.
def calc_loss(img, model): # Pass forward the image through the model to retrieve the activations. # Converts the image into a batch of size 1. img_batch = tf.expand_dims(img, axis=0) layer_activations = model(img_batch) if len(layer_activations) == 1: layer_activations = [layer_activations] losses = [] for act in layer_activations: loss = tf.math.reduce_mean(act) losses.append(loss) return tf.reduce_sum(losses)
Once you have calculated the loss for the chosen layers, all that is left is to calculate the gradients with respect to the image, and add them to the original image.
class DeepDream(tf.Module): def __init__(self, model): self.model = model @tf.function( input_signature=( tf.TensorSpec(shape=[None,None,3], dtype=tf.float32), tf.TensorSpec(shape=[], dtype=tf.int32), tf.TensorSpec(shape=[], dtype=tf.float32),) )def __call__(self, img, steps, step_size): print("Tracing") loss = tf.constant(0.0) for n in tf.range(steps): with tf.GradientTape() as tape: # This needs gradients relative to `img` # `GradientTape` only watches `tf.Variable`s by default tape.watch(img) loss = calc_loss(img, self.model) # Calculate the gradient of the loss with respect to the pixels of the input image. gradients = tape.gradient(loss, img) # Normalize the gradients. gradients /= tf.math.reduce_std(gradients) + 1e-8 # In gradient ascent, the "loss" is maximized so that the input image increasingly "excites" the layers. # You can update the image by directly adding the gradients (because they're the same shape!) img = img + gradients*step_size img = tf.clip_by_value(img, -1, 1) return loss, imgdeepdream = DeepDream(dream_model)
For displaying the preliminary DeepDream image, we need the Main Loop function as follows:
def run_deep_dream_simple(img, steps=100, step_size=0.01): # Convert from uint8 to the range expected by the model. img = tf.keras.applications.inception_v3.preprocess_input(img) img = tf.convert_to_tensor(img) step_size = tf.convert_to_tensor(step_size) steps_remaining = steps step = 0 while steps_remaining: if steps_remaining>100: run_steps = tf.constant(100) else: run_steps = tf.constant(steps_remaining) steps_remaining -= run_steps step += run_steps loss, img = deepdream(img, run_steps, tf.constant(step_size)) display.clear_output(wait=True) show(deprocess(img)) print ("Step {}, loss {}".format(step, loss)) result = deprocess(img) display.clear_output(wait=True) show(result) return result
For displaying the image:
dream_img = run_deep_dream_simple(img=original_img, steps=100, step_size=0.01)Output:

The output of the preliminary image is noisy with the low resolution in the image, and the pattern in the same granularity. By applying gradient ascent at different scales, we can address all these problems. This will allow patterns generated at smaller scales to be incorporated into patterns at higher scales and filled in with additional detail.
To do this, you can perform the previous gradient ascent approach, then increase the size of the image (which is referred to as an octave), and repeat this process for multiple octaves.
import timestart = time.time()OCTAVE_SCALE = 1.30img = tf.constant(np.array(original_img))base_shape = tf.shape(img)[:-1]float_base_shape = tf.cast(base_shape, tf.float32)for n in range(-2, 3): new_shape = tf.cast(float_base_shape*(OCTAVE_SCALE**n), tf.int32) img = tf.image.resize(img, new_shape).numpy() img = run_deep_dream_simple(img=img, steps=50, step_size=0.01)display.clear_output(wait=True)img = tf.image.resize(img, base_shape)img = tf.image.convert_image_dtype(img/255.0, dtype=tf.uint8)show(img)fname = 'deepdream_nicoleviolin_octave.png'PIL.Image.fromarray(np.array(img)).save(fname)end = time.time()end-start
Output:

For large images, we can split them into tiles and compute the gradient for each tile in order to avoid issues related to running time and memory for the gradient calculation. Applying random shifts to the image before each tiled computation prevents tile seams from appearing.
The result of this code implementation looks something like this:

Neural Style Transfer (NST)
It is a technique that allows us to generate an image with the same “content” as a base image, but with the “style” of our chosen picture.
The required inputs are as follows:
- Content image: an image to which we want to transfer style to
- Style image: the style we want to transfer to the content image
- Input image (generated): the final blend of content and style image
NST builds on the fact to blend the content image to a style reference image such that the content is painted in the specific style. NST employs a pre-trained CNN for feature extraction and the separation of content and style representations from an image.
NST network has two inputs: Content image and Style image. The content image is recreated as a newly generated image which is the only trainable variable in the neural network.
The architecture of the model performs the training using two loss terms — Content Loss and Style Loss:
- Content loss is calculated by measuring the difference between the higher-level intermediate layer feature maps.
- Style loss can be measured by the degree of correlation between the responses from different filters at a level.
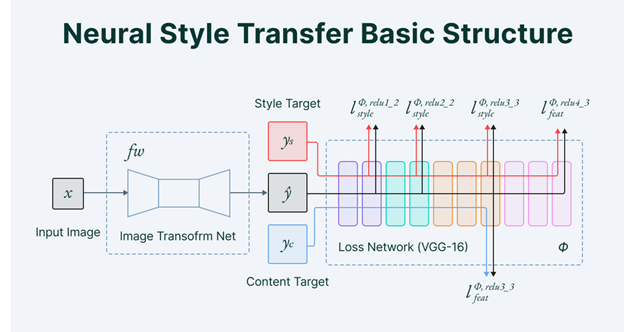
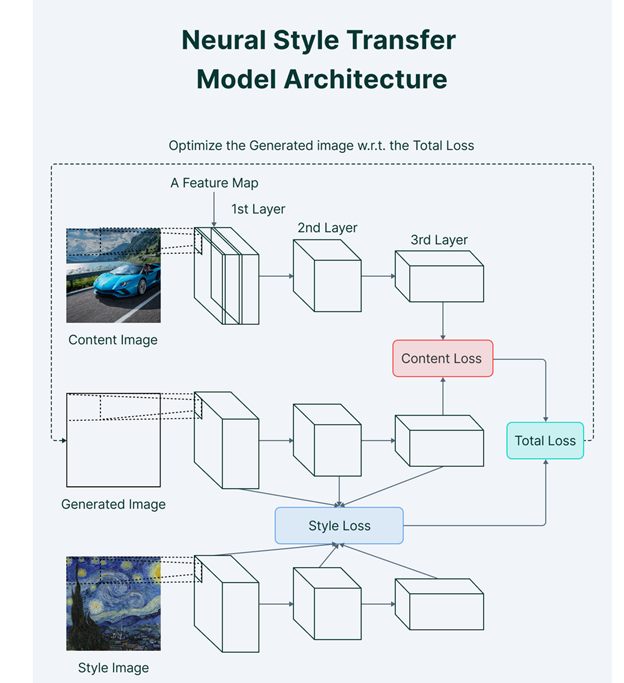
NST — Hands-On Experiment with Python:
We are using the same input image file from DeepDream hands-on exercise: data
Hands-on code for NST is from this TensorFlow Tutorial.
Let’s import the following python libraries and models:
import osimport tensorflow as tf# Load compressed models from tensorflow_hubos.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'import IPython.display as displayimport matplotlib.pyplot as pltimport matplotlib as mplmpl.rcParams['figure.figsize'] = (12, 12)mpl.rcParams['axes.grid'] = Falseimport numpy as npimport PIL.Imageimport timeimport functools
Let’s configure modules:
def tensor_to_image(tensor): tensor = tensor*255 tensor = np.array(tensor, dtype=np.uint8) if np.ndim(tensor)>3: assert tensor.shape[0] == 1 tensor = tensor[0] return PIL.Image.fromarray(tensor)
Let’s download images and choose a style image and a content image:
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')Output:Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg
196608/195196 [==============================] - 0s 0us/step
204800/195196 [===============================] - 0s 0us/step
Let’s visualize the input. First, we need to define a function to load an image and limit its maximum dimension to 512 pixels. For the input image file, as the resolution is small, we do not need to limit its maximum dimension, so we will use a different function.
# for the style content
def load_img(path_to_img): max_dim = 512 img = tf.io.read_file(path_to_img) img = tf.image.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.float32) shape = tf.cast(tf.shape(img)[:-1], tf.float32) long_dim = max(shape) scale = max_dim / long_dim new_shape = tf.cast(shape * scale, tf.int32) img = tf.image.resize(img, new_shape) img = img[tf.newaxis, :] return img# for the input image file:def load_img2(path_to_img): img = tf.io.read_file(path_to_img) img = tf.image.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.float32) shape = tf.cast(tf.shape(img)[:-1], tf.float32) img = img[tf.newaxis, :] return img
We also need to create a simple function to display an image:
def imshow(image, title=None): if len(image.shape) > 3: image = tf.squeeze(image, axis=0) plt.imshow(image) if title: plt.title(title)
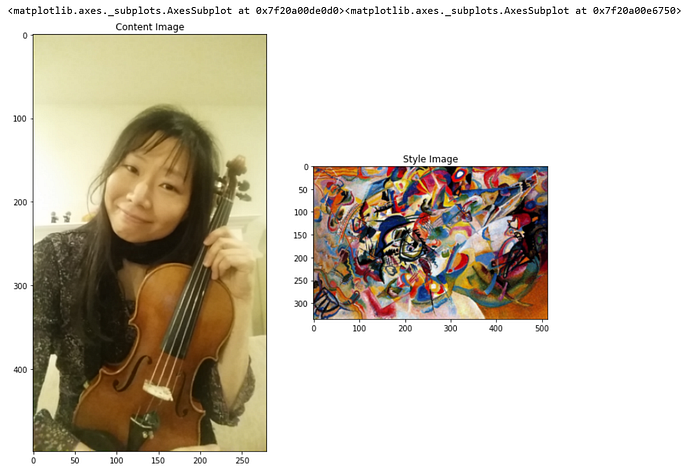
import matplotlib.pyplot as pltimport matplotlib.image as mpimg#content_image = load_img(content_path)#content_image = mpimg.imread('/content/nicole_violin.JPG')content_image = load_img2('/content/nicole_violin.png')style_image = load_img(style_path)plt.subplot(1, 2, 1)imshow(content_image, 'Content Image')plt.subplot(1, 2, 2)imshow(style_image, 'Style Image')
Output:
The very simple way to perform NST is via the fast style transfer using TensorFlow Hub model as follows:
import tensorflow_hub as hubhub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]tensor_to_image(stylized_image)Output:

To build a model using a neural network for NST, we need to first define the content and style representations of the image, using the intermediate layers of the model. The model can be further defined with tf.keras.applications and using the keras functional API. Then, the model is further developed by calculating style, extracting style and content, running the gradient descent, decreasing high frequency artifacts using an explicit regularization term (i.e. total variation loss) and re-running the optimization.
This process produces the following output:

We can try this process with a different style image. Let’s try with ‘Two Young Girls at the Piano’ by Auguste Renoir as a style image:
style_path = tf.keras.utils.get_file('renoir_piano.jpg','https://images.metmuseum.org/CRDImages/rl/original/DT3131.jpg')Output:Downloading data from https://images.metmuseum.org/CRDImages/rl/original/DT3131.jpg
3121152/3113774 [==============================] - 0s 0us/step
3129344/3113774 [==============================] - 0s 0us/step

With the same NST code above, the output images look something like these:


Detailed code for generating a NST output through neural net optimization can be found in this TensorFlow Tutorial for NST.
Conclusion
AI Art has so much depth and levels that inspire us, and it has the potential and opportunities in enhancing, influencing and shaping our minds. There are challenges and grey areas in the AI Art space, however. AI technology is considered as disruption, especially in the art domain, and images generated from AI are commercialized without copyright protection, and without the law or regulation to restrict and control the ‘black market’.
The cutting-edge AI technology such as DALL-E or DALL-E2 has the limitation related to AI bias and ethical concerns, although DALL-E2 improved some of those issues. As these models learn from large amounts of data that can contain bias, the output generated from these systems can show bias against women and people of color. Audio, text, images and videos can be forged to create terrifying deepfakes and spread disinformation.
Yet, it continues to evolve as a promising prospect to enrich our minds and society as a whole.
References:
- https://en.wikipedia.org/wiki/Artificial_intelligence_art
- https://wiki.pathmind.com/generative-adversarial-network-gan
- https://learn.adafruit.com/generating-ai-art-with-vqgan-clip
- https://ai.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html
- https://fortune.com/40-under-40/2019/ian-goodfellow/
- https://www.codemotion.com/magazine/video/ai-art-and-design-from-deep-dream-to-gans/
- https://www.lexology.com/library/detail.aspx?g=88b40477-a2f5-4385-a055-fb14e567a569
- https://research.adobe.com/news/image-stylization-history-and-future-part-3/
- https://www.katevassgalerie.com/blog/harold-cohen-aaron-computer-art
- https://becominghuman.ai/with-gans-world-s-first-ai-generated-painting-to-recent-advancement-of-nvidia-b08ddfda45b1
- https://www.technologyreview.com/2018/02/21/145289/the-ganfather-the-man-whos-given-machines-the-gift-of-imagination/
- https://thereader.mitpress.mit.edu/deepdream-how-alexander-mordvintsev-excavated-the-computers-hidden-layers/
- https://news.artnet.com/art-world/dall-e-2098779
- https://www.nytimes.com/2022/04/06/technology/openai-images-dall-e.html
- https://openai.com/blog/clip/
- https://openai.com/blog/dall-e/
- https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf
- https://www.vox.com/future-perfect/23023538/ai-dalle-2-openai-bias-gpt-3-incentives
- https://www.v7labs.com/blog/neural-style-transfer
- https://analyticsindiamag.com/comprehensive-guide-to-dall-e-by-openai-creating-images-from-text/
- https://www.forbes.com/sites/anniebrown/2021/09/06/is-artificial-intelligence-set-to-take-over-the-art-industry/?sh=54c3a4e533c5
- https://hai.stanford.edu/news/artists-intent-ai-recognizes-emotions-visual-art
- https://www.tensorflow.org/tutorials/generative/deepdream
- https://www.tensorflow.org/tutorials/generative/style_transfer
